Nội dung bài viết
Bài viết không index làm đứt gãy luồng phân phối lưu lượng truy cập tự nhiên và gây lãng phí nghiêm trọng nguồn lực sản xuất nội dung của doanh nghiệp. Nút thắt kỹ thuật này không xuất phát từ chất lượng văn bản mà bắt nguồn từ các xung đột trong tệp lệnh điều hướng bot, sự thiếu hụt liên kết nội bộ hoặc ngân sách quét trên tên miền đã cạn kiệt. IDEEN MEDIA phân tích chi tiết bản chất lỗi hạ tầng cấu trúc web và hướng dẫn quy trình định tuyến lại thuật toán, ép hệ thống nạp dữ liệu URL lên bảng xếp hạng tìm kiếm.
Bài viết không index do trình thu thập dữ liệu Googlebot bị chặn bởi các lệnh cấm trong tệp robots.txt hoặc giới hạn tài nguyên quét. Thuật toán từ chối nạp dữ liệu nếu phát hiện trang bị cô lập hoàn toàn khỏi luồng liên kết nội bộ hoặc tồn tại thẻ báo lỗi định tuyến trên mã nguồn HTML.
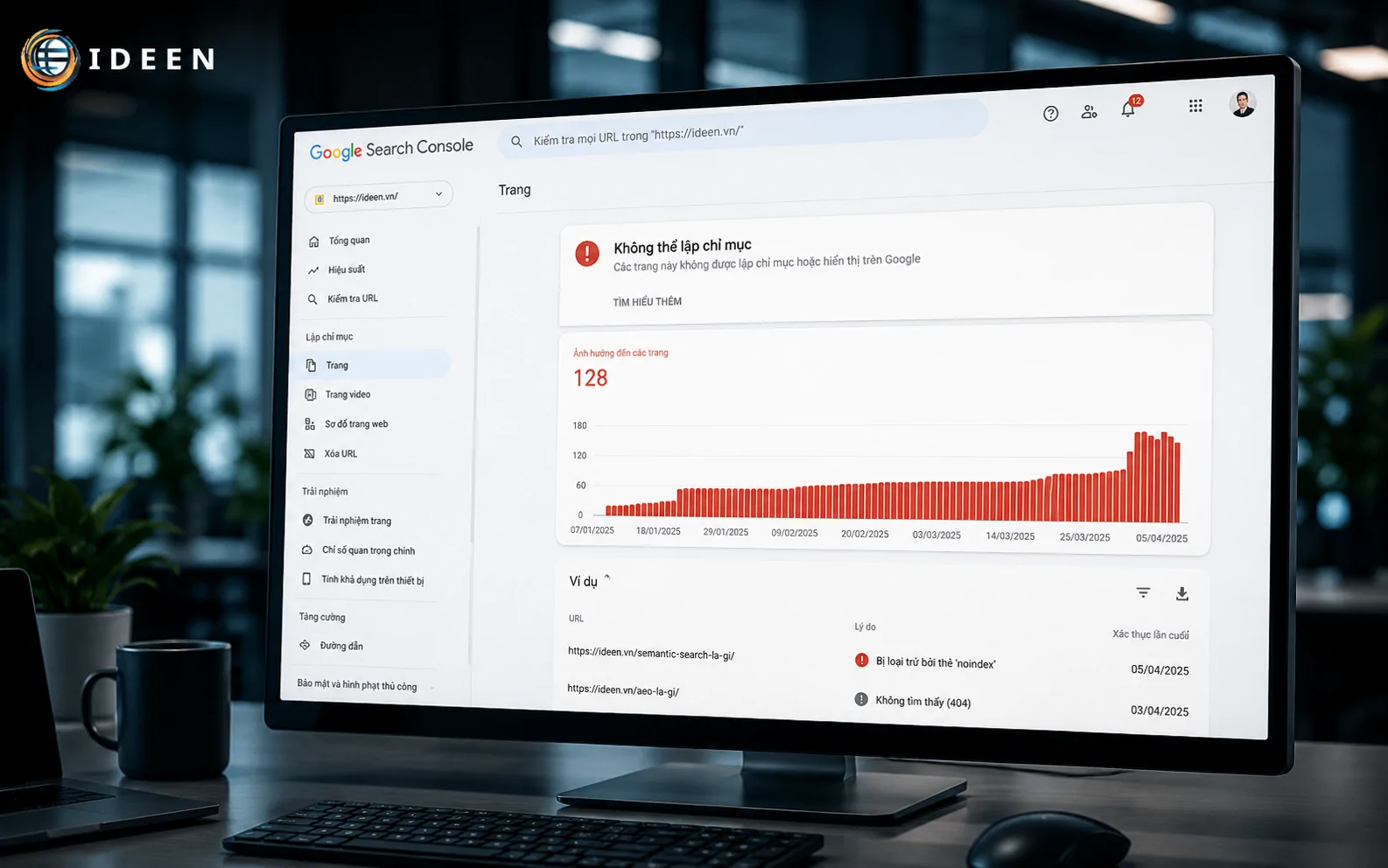
Tệp robots.txt là chốt chặn đầu tiên kiểm soát luồng di chuyển của trình thu thập dữ liệu. Một thiết lập cú pháp sai lệch lập tức tạo ra rào cản từ chối bot truy cập vào các thư mục trọng yếu, gây ra tình trạng bài viết không index đồng loạt trên nhiều danh mục nội dung.
Cấu trúc web quy mô lớn thường sử dụng lệnh Disallow để bảo vệ luồng truy cập vào các trang giỏ hàng, trang quản trị tài khoản người dùng hoặc hệ thống thanh toán. Quản trị viên thường sử dụng ký tự đại diện (wildcard) như dấu sao (*) hoặc dấu chấm hỏi (?) để thiết lập quy tắc chặn hàng loạt. Việc thiết lập chuỗi biểu thức chính quy (regex) không chặt chẽ vô tình chặn nhầm các cấu trúc URL bài viết tiêu chuẩn. Thuật toán của Google ghi nhận tệp lệnh này với mức ưu tiên cao nhất, lập tức hủy bỏ phiên quét dữ liệu ngay tại ngưỡng cửa tên miền.
Bên cạnh đó, việc vô tình chặn các tệp tin thực thi thiết kế như CSS hay JavaScript (.js) khiến trình thu thập không thể kết xuất (Rendering) toàn vẹn giao diện người dùng. Khi hệ thống AI phân tích DOM (Document Object Model) và nhận thấy giao diện bị vỡ nát, thuật toán đánh giá đây là một trang lỗi. Rào cản kỹ thuật này trực tiếp hủy bỏ tư cách xếp hạng của tài nguyên, tạo ra lỗi bài viết không index kéo dài mà không phát ra bất kỳ cảnh báo mã HTTP nào trên hệ thống đo lường thông thường.
Để khắc phục điểm nghẽn này, người làm Technical SEO trực tiếp sử dụng công cụ kiểm tra tệp robots.txt tích hợp sẵn trên giao diện Search Console cũ. Nhập chính xác đường dẫn bài viết đang gặp lỗi vào thanh kiểm tra, hệ thống mô phỏng tức thời hành vi của bot và trả về kết quả định lượng rõ ràng: "Được phép" (Allowed) hoặc "Bị chặn" (Blocked), kèm theo dòng lệnh gây lỗi cụ thể bị bôi đỏ.
Gỡ bỏ lệnh chặn sai lệch khỏi môi trường máy chủ và gửi yêu cầu cập nhật lại tệp tin giúp Googlebot nhanh chóng định tuyến lại luồng quét an toàn. Thiết lập lại cấu trúc lệnh User-agent: * kết hợp Allow: / cho toàn bộ tài nguyên thông tin công khai. Mở khóa tầng rào cản sơ cấp này là thao tác bắt buộc dọn đường cho thuật toán nạp dữ liệu trang đích vào cơ sở dữ liệu phân tích. Quá trình kiểm tra tệp lệnh cần được đưa vào quy trình duy tu cấu trúc hàng tháng để chặn đứng rủi ro bài viết không index tái diễn.
Thuật toán Google cấp phát một lượng tài nguyên xử lý dữ liệu nhất định, gọi là crawl budget (ngân sách thu thập), để quét mỗi tên miền theo chu kỳ. Nếu cấu trúc web tồn tại quá nhiều vòng lặp liên kết, bot sẽ tiêu tốn toàn bộ ngân sách này trước khi chạm đến các nội dung mới xuất bản, tạo ra độ trễ cập nhật hệ thống cực kỳ nghiêm trọng.
Trang mồ côi ( orphan page ) là định nghĩa chỉ các bài viết đã xuất bản công khai trên dữ liệu nền tảng nhưng tuyệt đối không nhận được bất kỳ liên kết nội bộ (internal link) nào từ các trang khác trong cùng domain. Thuật toán định vị thông tin di chuyển thuần túy thông qua việc phân tích và bám theo các thẻ HTML href. Một trang hoàn toàn cô lập vật lý sẽ không nhận được bất kỳ luồng sức mạnh tín nhiệm (PageRank) nào chảy từ trang chủ hay trang danh mục gốc.
Hệ thống đánh giá sự cô lập này là dấu hiệu của một tài nguyên vô giá trị hoặc bị chính người tạo ra nó bỏ rơi. Mức độ ưu tiên thu thập bị giáng xuống mức 0. Hiện tượng rò rỉ cấu trúc này trực tiếp sinh ra hệ quả bài viết không index, bất chấp việc đường dẫn đã được khai báo thủ công lên sitemap.xml. Độ sâu nhấp chuột (Click Depth) vượt quá 4 cấp độ tính từ trang chủ cũng tạo ra hiệu ứng mồ côi tương tự, khiến bot bỏ cuộc giữa chừng.
Quá trình định tuyến liên kết này đặc biệt phát huy hiệu suất cấp phát tín hiệu tối đa khi kết hợp triển khai content entity chuyên sâu, giúp thuật toán phân tách ngữ nghĩa dễ dàng nhóm các bài viết rời rạc thành một cụm chủ đề (cluster) mạch lạc. Tín hiệu ngữ nghĩa rõ ràng buộc hệ thống máy chủ của Google cấp phát hạn mức băng thông lớn hơn cho cụm nội dung đó. Nút thắt cổ chai luồng thu thập dữ liệu bị phá vỡ, chấm dứt triệt để tình trạng bài viết không index ở các nội dung ngách phân tầng sâu.
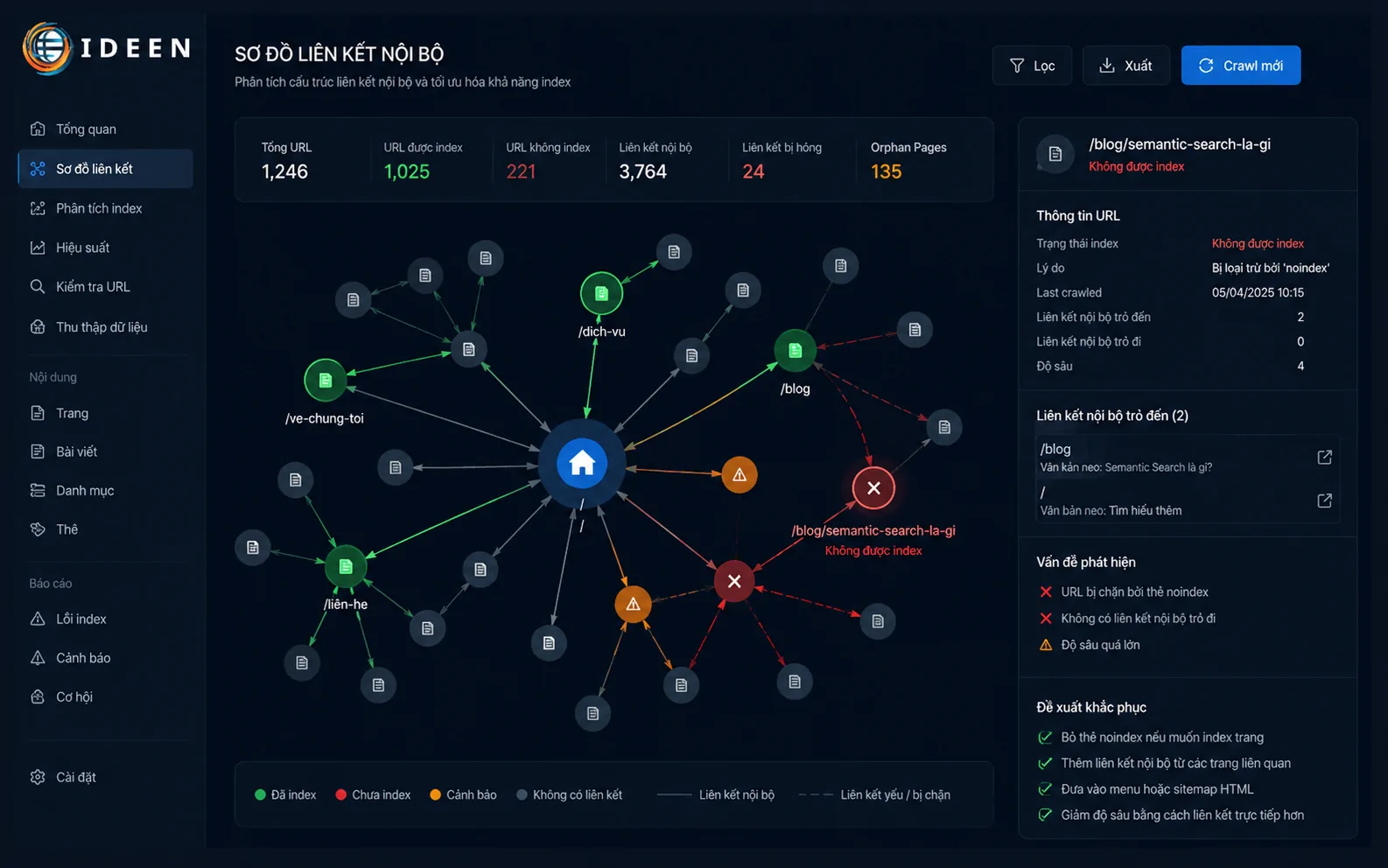
Kiểm soát rủi ro bài viết không index không phải là thao tác chờ đợi thụ động. Kỹ sư tối ưu cần chủ động áp dụng quy trình kiểm tra mã nguồn tuần tự từ tầng hiển thị đến tầng khai báo dữ liệu API.
Bảng phân loại mức độ nghiêm trọng nguyên nhân từ chối lập chỉ mục trên GSC:
Xung đột thuật toán giữa các plugin SEO nền tảng hoặc lỗi đồng bộ quá trình chuyển đổi giao diện thường tự động chèn thêm thẻ vào thẻ của bài viết. Mã cấm hiển thị này phát tín hiệu phủ quyết mạnh nhất, buộc bot loại bỏ URL khỏi cơ sở dữ liệu ngay lập tức. Thao tác mở mã nguồn (Ctrl + U), sử dụng lệnh tìm kiếm để truy xuất và xóa bỏ toàn bộ cú pháp noindex tag dư thừa là yêu cầu tối quan trọng để chấm dứt tình trạng bài viết không index.
Đồng thời, kỹ sư cần kiểm tra sự tồn tại của thẻ chuẩn tắc Canonical. Nếu bài viết mới chứa thẻ trỏ hướng về một URL khác, hệ thống sẽ mặc định đây là nội dung trùng lặp và vĩnh viễn không index trang này.
Sơ đồ sitemap hoạt động như một bản đồ dẫn đường trực tiếp, chỉ định mức độ ưu tiên thu thập các nội dung mới nhất. Rà soát hệ thống đảm bảo đường dẫn bài viết không index đã được cập nhật toàn vẹn vào tệp sitemap.xml cùng với thông số
Sử dụng công cụ Kiểm tra URL, dán đường dẫn trực tiếp vào thanh công cụ tìm kiếm nội bộ GSC. Chờ thuật toán truy xuất kết quả môi trường máy chủ trực tiếp. Click nút "Yêu cầu lập chỉ mục" để đẩy URL vào hàng đợi xử lý ưu tiên của trung tâm dữ liệu. Hành động ping hệ thống trực tiếp này khai báo cho Googlebot biết mã lỗi kỹ thuật đã được dọn dẹp. Nếu trang web đáp ứng đủ mật độ thực thể và độ trễ tải trang ổn định, thuật toán sẽ thay đổi trạng thái bài viết không index trong đợt đối chiếu dữ liệu kế tiếp.
Điều hướng dòng truy cập thực tế (User signal) trực tiếp từ trang chủ hoặc bài viết lọt top có lưu lượng lớn nhất trỏ về trang đích đang lỗi thông qua liên kết nội bộ ngữ cảnh. Tín hiệu nhấp chuột của người dùng kích hoạt thuật toán ưu tiên quét lại toàn bộ DOM HTML của liên kết đích. Áp lực từ lưu lượng truy cập thực tế đẩy nhanh tốc độ duyệt trang gấp nhiều lần, là thao tác chốt hạ xóa sổ hoàn toàn hiện tượng bài viết không index cứng đầu.
Quá trình phân tích mã lỗi hệ thống đo lường thường phát sinh các thông báo trạng thái gây nhiễu loạn về hành vi của trình thu thập dữ liệu.
Trạng thái này xác nhận bot đã hoàn tất việc trườn theo liên kết, đọc hiểu mã nguồn nhưng hệ thống đánh giá nội dung chưa đủ trọng số hoặc đang dính lỗi trùng lặp cấu trúc. Thuật toán xếp URL vào hàng đợi xử lý định kỳ, cần bổ sung độ dày ngữ nghĩa hoặc gom cụm nội dung để tăng tín hiệu định danh, tránh để tình trạng bài viết không index kéo dài vô thời hạn. Mật độ thông tin quá mỏng (Thin Content) sẽ khiến URL mãi mãi kẹt ở trạng thái này.
Thông báo này chỉ ra ngân sách thu thập tài nguyên dành riêng cho tên miền đã cạn kiệt hoặc máy chủ có độ trễ phản hồi quá cao, buộc bot phải từ chối kết nối. Quản trị viên cần dọn dẹp các đường dẫn chuyển hướng sai, xóa bỏ lỗi 404 và tối ưu tốc độ phản hồi (TTFB) dưới 200ms để tạo khoảng trống băng thông. Khi băng thông thông thoáng, thuật toán mới có không gian nạp dữ liệu văn bản mới.
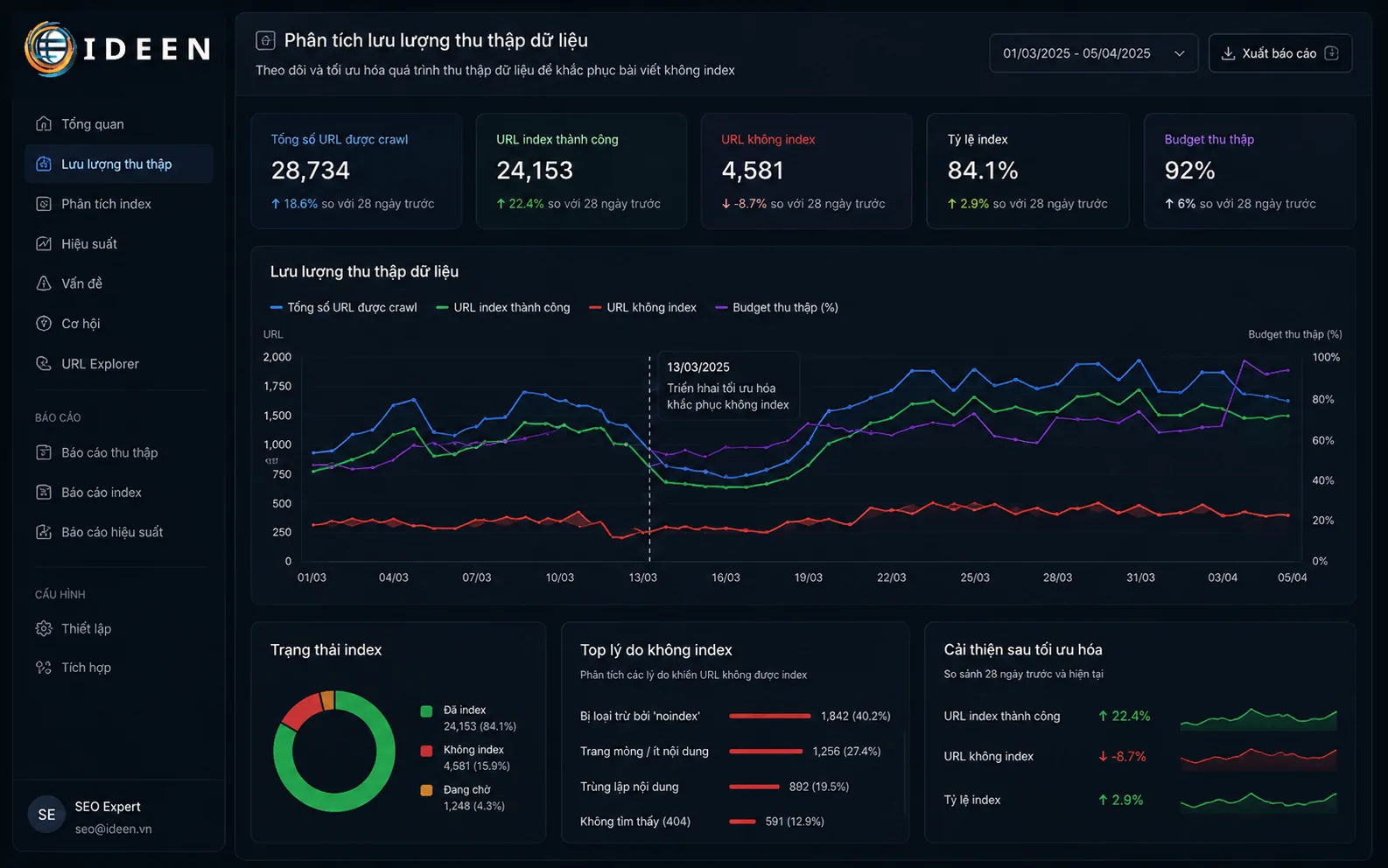
Việc đổi định dạng URL mà không cấu hình mã trạng thái 301 Redirect lập tức phá vỡ điểm chạm cấu trúc, tạo ra lỗi HTTP 404 Not Found diện rộng. Đường dẫn mới được sinh ra sẽ phải xếp hàng chờ kiểm duyệt lại từ đầu như một URL hoàn toàn xa lạ. Tình trạng bài viết không index vẫn lặp lại y nguyên nếu quản trị viên không giải quyết triệt để lỗi trang mồ côi hoặc gỡ bỏ các đoạn mã cấm thu thập trong khung HTML gốc.
👉 Xem thêm : ➔ THIẾT LẬP CẤU TRÚC INTERNAL LINK SILO ĐIỀU HƯỚNG DÒNG CHẢY PAGERANK
Xây dựng một kiến trúc liên kết nội bộ silo mạch lạc, điều hướng luồng Pagerank theo cụm chủ đề chuẩn xác và kiểm soát chặt chẽ ngân sách thu thập là phương pháp cốt lõi loại bỏ vĩnh viễn rủi ro bài viết không index. Việc ấn nút yêu cầu thụ động trên bảng điều khiển chỉ giải quyết các triệu chứng bề mặt. Một hệ thống nền tảng phân tầng rõ ràng, sạch mã lỗi cấm quét sẽ tự động xác lập quyền ưu tiên truy xuất cao nhất với thuật toán tìm kiếm. Thiết lập lại cấu trúc thực thể chuẩn AEO là bước đi bắt buộc. Liên hệ IDEEN MEDIA qua hotline 0917.500.229 để đánh giá độ trễ hệ thống, rà soát lại toàn bộ quy trình thiết lập nền tảng kỹ thuật.
Thông tin liên hệ:
(1).webp)
CÔNG TY CP CÔNG NGHỆ VÀ TRUYỀN THÔNG Ý TƯỞNG IDEEN
Địa chỉ cũ: 64 Trương Định, Phường Võ Thị Sáu, Quận 3, TP. HCM
Địa chỉ mới: Số 64 Trương Định - phường Xuân Hòa, TP. Hồ Chí Minh
Hotline: 0917 500 229
Email: vanphongideenmedia@gmail.com
Website: contentchuanseo.com











{kind=link}