Nội dung bài viết
Quy trình Tối ưu Semantic Search đòi hỏi sự can thiệp trực tiếp vào cấu trúc toán học của ngôn ngữ. Thuật toán Google hiện hành không đếm tần suất xuất hiện của văn bản; chúng đo lường khoảng cách vector và phân tích ngữ cảnh chéo. Bài viết này định lượng các chỉ số kỹ thuật cốt lõi để tái cấu trúc văn bản thành dữ liệu máy học. Việc loại bỏ hoàn toàn phương thức thao túng mật độ từ khóa lạc hậu là bắt buộc. Mục tiêu duy nhất là thiết lập một hệ thống dữ liệu tinh khiết, đáp ứng chính xác cơ chế truy xuất trực tiếp của các mô hình ngôn ngữ lớn (LLMs).
Tối ưu Semantic Search vận hành dựa trên cơ chế phân tích khoảng cách toán học giữa các nút thực thể thay vì đối chiếu mặt chữ. Phương pháp lõi để đạt Top 0 nhanh nhất là định dạng dữ liệu thô bằng cấu trúc AEO, kết hợp thiết lập trọng số từ vựng trực diện ngay tại các đoạn phản hồi.
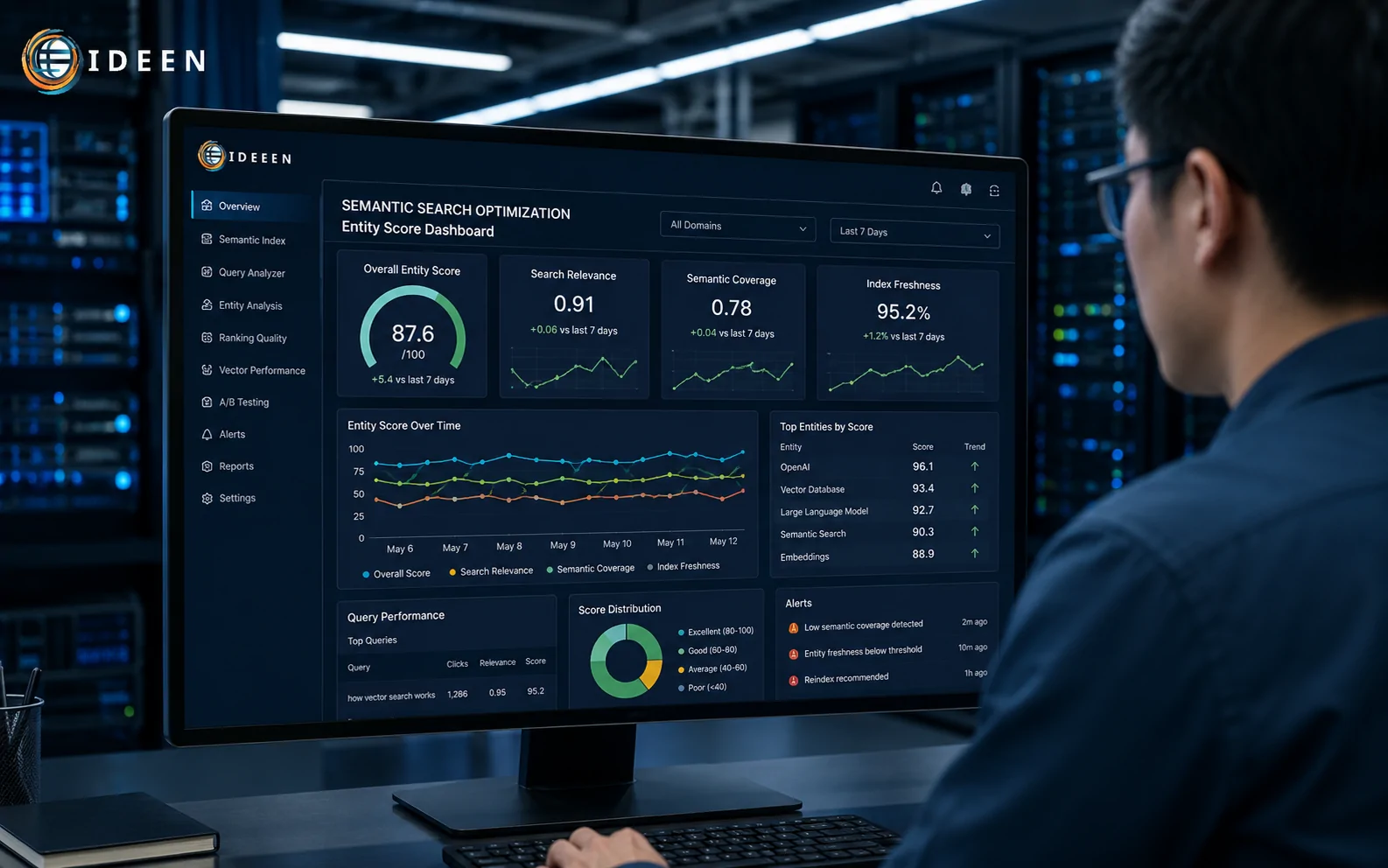
Mật độ từ khóa đã chết. Việc cố gắng lặp lại một cụm từ nhất định theo tỷ lệ phần trăm cố định vi phạm trực tiếp nguyên tắc tổ chức văn bản tự nhiên. Thuật toán lõi của Google ưu tiên đo lường trọng số phân bổ thay vì số lần lặp lại cơ học.
Cơ chế TF-IDF (Term Frequency-Inverse Document Frequency) đánh giá tầm quan trọng của một từ vựng dựa trên tần suất nó xuất hiện trong một văn bản cụ thể so với toàn bộ tập dữ liệu (corpus). Từ vựng xuất hiện nhiều trong một bài nhưng hiếm gặp ở các bài khác sẽ nhận trọng số cực cao. Quá trình Tối ưu Semantic Search yêu cầu người vận hành xác định chính xác các từ vựng đặc thù mang tính kỹ thuật, thay vì rải rác các từ khóa vô nghĩa. Khi thuật toán quét qua, điểm TF-IDF cao tại các nút thông tin cụ thể gửi đi tín hiệu sắc nét về chủ đề lõi, triệt tiêu sự nhiễu loạn từ các liên từ hay giới từ phổ thông. Không gian phân phối từ vựng trở thành biểu đồ nhiệt (heatmap). Mật độ dày đặc tại các điểm mù kỹ thuật gia tăng chỉ số xếp hạng trung bình (Average Position).
Hệ thống Natural Language Processing vận hành qua các mô hình Transformer phân tích hai chiều (Bidirectional). Điều này có nghĩa là thuật toán quét văn bản từ trái sang phải và ngược lại cùng một lúc. Nó đánh giá nghĩa của một từ dựa trên toàn bộ bối cảnh bao quanh nó. Kỹ thuật Masked Language Modeling cho phép AI dự đoán từ bị khuyết, từ đó đo lường mức độ logic của câu. Việc chèn từ khóa sai ngữ pháp lập tức kích hoạt bộ lọc spam tự động. Google BERT và MUM biến đổi từng đoạn văn thành hàng chuỗi token liên kết. Việc chia nhỏ thông tin ra thành các token siêu nhỏ giúp máy tính hiểu được các sắc thái phức tạp, từ đồng âm khác nghĩa và xử lý triệt để các truy vấn dạng hội thoại phức hợp.
Khái niệm lưới ngữ nghĩa đại diện cho mạng lưới các mối quan hệ tĩnh giữa các đối tượng. Để nội dung không bị đánh giá là mỏng (thin content), cấu trúc bài viết phải mô phỏng lại cách não bộ con người lưu trữ và liên kết thông tin.
Thuật toán Vector search chuyển hóa từng từ vựng thành một dãy số học thực (thường là 768 chiều đối với mô hình BERT tiêu chuẩn). Mỗi từ trở thành một điểm tọa độ trong không gian đa chiều. Khoảng cách giữa các điểm này được tính toán bằng chỉ số Cosine Similarity. Góc giữa hai vector càng nhỏ, độ tương đồng ngữ nghĩa càng lớn. Mấu chốt của Tối ưu Semantic Search nằm ở việc nhóm các cụm từ có khoảng cách vector gần nhau vào cùng một phân đoạn H2/H3. Ví dụ, cụm "băng thông", "độ trễ", và "bộ định tuyến" có hệ số góc siêu nhỏ. Khi xuất hiện cạnh nhau, chúng cộng hưởng và đẩy Salience Score của cụm chủ đề lên mức tối đa. Thuật toán không cần đọc từ khóa chính, nó nội suy ra chủ đề lõi dựa trên tọa độ của các vector vệ tinh bao quanh.
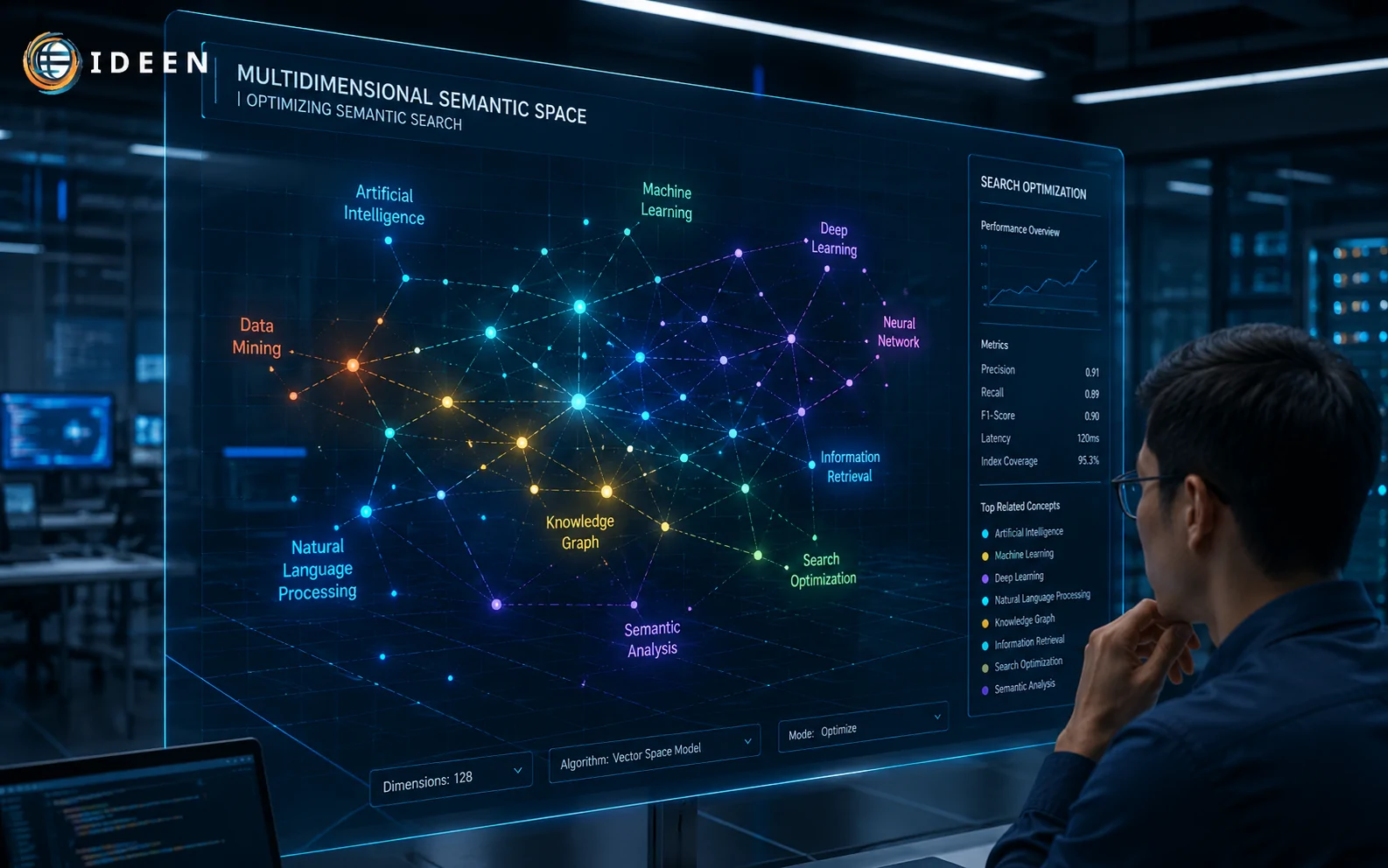
Thực thể không phải là từ khóa. Thực thể là một đối tượng xác định độc nhất (một người, một địa điểm, một khái niệm vật lý) mang mã định danh riêng biệt trên đồ thị tri thức (Knowledge Graph). Giao thức Entity SEO hoạt động như một lớp mã vạch (barcode) dán lên từng khái niệm trong bài. Việc Tối ưu Semantic Search bắt buộc phải khai báo rõ các thực thể này thông qua hệ thống schema markup hoặc cú pháp định nghĩa chặt chẽ ngay trong đoạn văn. Khi thuật toán nhận diện được thực thể trung tâm, nó tự động đối chiếu với cơ sở dữ liệu toàn cầu của Google để xác thực mức độ chuyên gia (E-E-A-T) của văn bản.
Bảng Thông Số Tương Quan Giữa Intent Và Wordcount
|
Phân Loại Intent (Ý Định Tìm Kiếm) |
Tọa Độ Thực Thể Cốt Lõi |
Giới Hạn Wordcount Hiệu Suất Cao |
Chỉ Số Vector Trọng Tâm |
|
Thông tin kỹ thuật (Informational) |
Định nghĩa, Thuật ngữ, Tiêu chuẩn |
1800 - 2500 từ |
Khoảng cách vector hẹp, độ sâu Salience cao |
|
Chuyển đổi thương mại (Transactional) |
Giá bán, Thông số, So sánh |
800 - 1200 từ |
Tốc độ load token nhanh, Direct Answer |
|
Điều hướng hệ thống (Navigational) |
Tên thương hiệu, Nền tảng lõi |
500 - 800 từ |
Exact match vector, Internal link dày đặc |
|
Mở rộng chủ đề (Investigational) |
Review, Phân tích chéo, Báo cáo |
2000 - 3000 từ |
Lưới ngữ nghĩa rộng, Vector đa chiều |
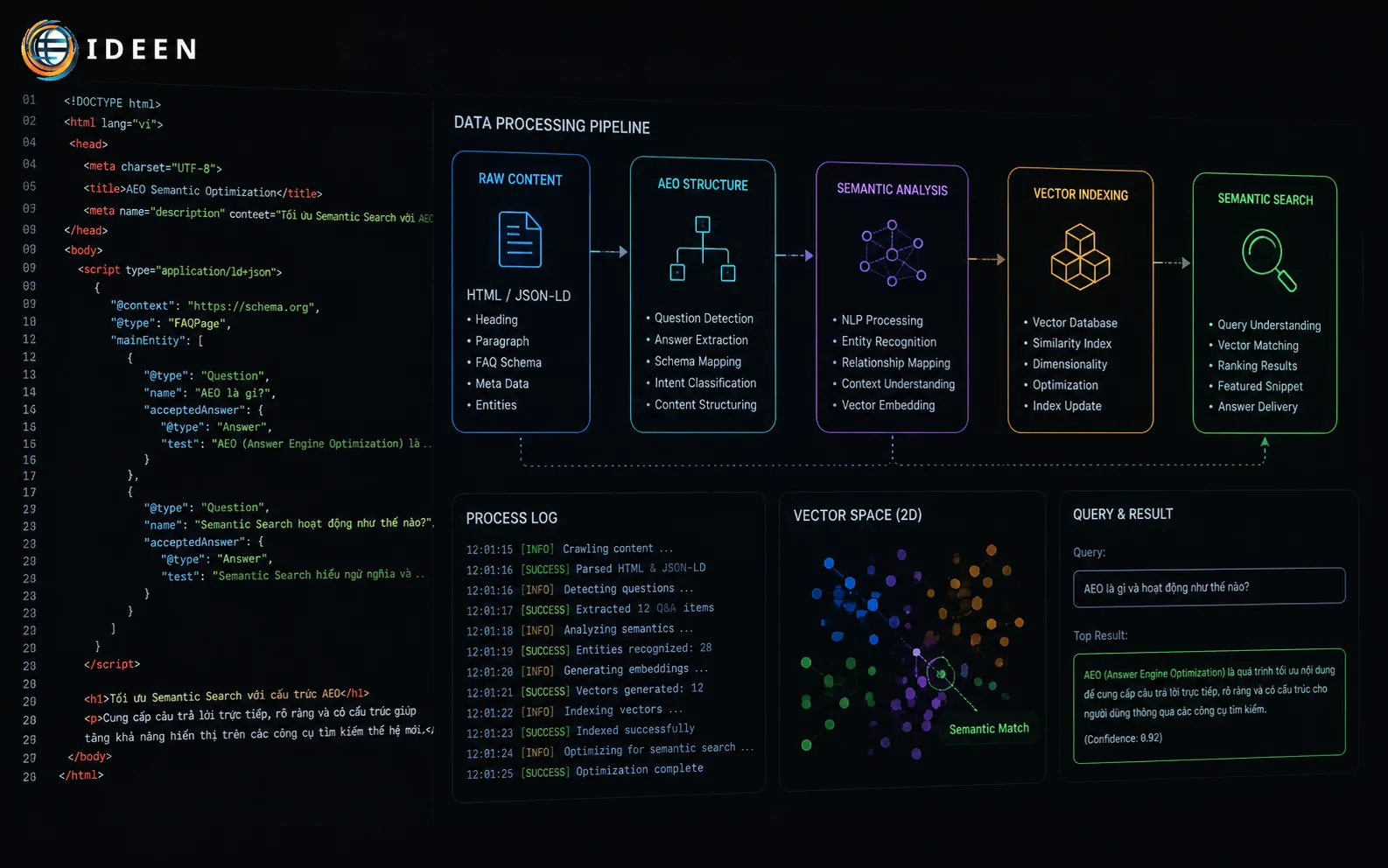
Chuẩn hóa AEO là quá trình loại bỏ sự mơ hồ trong cú pháp. Cấu trúc AEO định hình lại cách trình bày dữ liệu thô để các công cụ tìm kiếm tạo sinh (SGE) dễ dàng trích xuất và biến thành câu trả lời tức thì. Không áp dụng AEO, Tối ưu Semantic Search chỉ dừng lại ở mức lý thuyết mà không thể bứt phá lên vị trí Featured Snippet.
Dữ liệu trả về từ trang kết quả tìm kiếm (SERP) cung cấp chính xác sơ đồ tư duy của máy học. Quy trình quy hoạch cụm thông tin được thiết lập qua ba thao tác tĩnh:
Máy học ghét các câu phức đa tầng. Cú pháp phức tạp làm tăng thời gian xử lý token (tokenization time) và giảm điểm tự tin (Confidence Score) của thuật toán đối với câu văn. Cú pháp câu AEO chuẩn phải theo quy tắc S-V-O (Chủ ngữ - Động từ - Vị ngữ) ngắn gọn. Hạn chế sử dụng câu bị động. Loại bỏ trạng từ chỉ mức độ ("rất", "vô cùng", "cực kỳ"). Kỹ thuật kiểm soát độ nhiễu đòi hỏi người thực thi viết nội dung chuẩn seo phải sắp xếp các node thực thể một cách chặt chẽ, cắt giảm tối đa các từ nối rườm rà cản trở dòng chảy xử lý ngữ nghĩa. Một cấu trúc câu trong suốt mang lại khả năng lập chỉ mục (indexing) tính bằng phút. Mức độ sắc nét của văn bản định hình hiệu suất của quá trình Tối ưu Semantic Search trên các máy chủ SGE.
Làm sao để đo lường định lượng mức độ tương thích ngữ nghĩa của một đoạn văn?
Sử dụng API Cloud Natural Language của Google để lấy chỉ số Salience Score. Khi hệ thống quét văn bản, nó sẽ trả về điểm số từ 0.0 đến 1.0 cho từng thực thể. Điểm số vượt ngưỡng 0.6 chứng minh việc thiết lập cụm từ khóa phụ đã đạt chuẩn kỹ thuật lõi. Quá trình Tối ưu Semantic Search thành công dựa trên hệ thống điểm tĩnh này.
Việc lặp lại từ khóa phụ nhiều lần có phá vỡ cấu trúc không gian vector không?
Thuật toán máy học sẽ trừng phạt hiện tượng nhồi nhét (keyword stuffing) bằng cách giảm chỉ số Cosine. Tần suất lặp lại cơ học làm biến dạng đồ thị lưới ngữ nghĩa, khiến AI nhận diện văn bản như một đoạn mã spam (spammy markup). Sự thay thế bằng các từ đồng nghĩa (synonyms) là giải pháp duy nhất.
Khoảng cách giữa các cụm từ (Word Proximity) ảnh hưởng đến việc thu thập dữ liệu thế nào?
Độ trễ thu thập dữ liệu tăng mạnh nếu các thực thể chính nằm cách xa nhau. Thuật toán Attention Mechanisms của Transformer quét theo bán kính cửa sổ (window size). Nếu khoảng cách vượt qua số lượng token giới hạn, sự liên kết ngữ nghĩa bị đứt gãy. Việc đưa các cụm từ trọng tâm lại gần nhau tối đa hóa sức mạnh của thao tác Tối ưu Semantic Search.
👉 Xem thêm : ➔ PHÂN TÍCH CHÊNH LỆCH CHI PHÍ VÀ ROI KHI THUÊ AGENCY SO VỚI IN-HOUSE
Tối ưu Semantic Search không phải là thủ thuật tạm thời; nó là giao thức mặc định của các hệ thống tìm kiếm sử dụng trí tuệ nhân tạo. Việc dịch chuyển từ tư duy đếm chữ sang kỹ thuật định lượng tọa độ không gian từ vựng phân định rõ khoảng cách giữa các hệ thống dữ liệu vững chắc và các website mỏng rỗng. Các hệ thống không thích ứng sẽ tự động bị loại bỏ khỏi đồ thị tri thức toàn cầu. Liên hệ IDEEN MEDIA qua hotline 0917.500.229 để thiết lập hạ tầng nội dung kỹ thuật số bám sát các giới hạn thuật toán mới nhất, tối đa hóa sức mạnh lưu trữ trực tiếp trên máy chủ phân tích của Google.
Thông tin liên hệ:
(1).webp)
CÔNG TY CP CÔNG NGHỆ VÀ TRUYỀN THÔNG Ý TƯỞNG IDEEN
Địa chỉ cũ: 64 Trương Định, Phường Võ Thị Sáu, Quận 3, TP. HCM
Địa chỉ mới: Số 64 Trương Định - phường Xuân Hòa, TP. Hồ Chí Minh
Hotline: 0917 500 229
Email: vanphongideenmedia@gmail.com
Website: contentchuanseo.com
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
 ĐỂ THỐNG TRỊ TOP 0")
{kind=link}