Nội dung bài viết
Tối ưu nội dung hiển thị trên ai search bắt đầu từ việc tái định hình cấu trúc dữ liệu lưu trữ trên máy chủ doanh nghiệp. Các hệ thống phản hồi hội thoại trực tiếp đang chiếm lĩnh lưu lượng truy cập từ các trang kết quả truyền thống, tạo ra khoảng trống lớn về tỷ lệ nhấp chuột. Doanh nghiệp mất dần dấu vết nhận diện do dữ liệu phân phối trên website thiếu tính liên kết thực thể, khiến trình quét thông tin phân tích sai lệch bối cảnh kỹ thuật. Trở ngại cốt lõi nằm ở việc phân tách ngôn ngữ tự nhiên thành các chuỗi dữ liệu định lượng có thể lập chỉ mục chính xác. Doanh nghiệp buộc phải áp dụng mô hình toán học ngữ nghĩa nhằm duy trì sự hiện diện thương hiệu trước các thuật toán thu thập thông tin tự động.
Tối ưu nội dung hiển thị trên ai search là quy trình cấu trúc hóa tài nguyên văn bản thành các nút thực thể giàu ngữ cảnh, giúp các mô hình ngôn ngữ lớn dễ dàng bóc tách thông tin. Doanh nghiệp thực hiện giải pháp này nhằm chiếm lĩnh vị trí trích dẫn hàng đầu, bảo vệ lưu lượng truy cập tự nhiên trên chatbot.
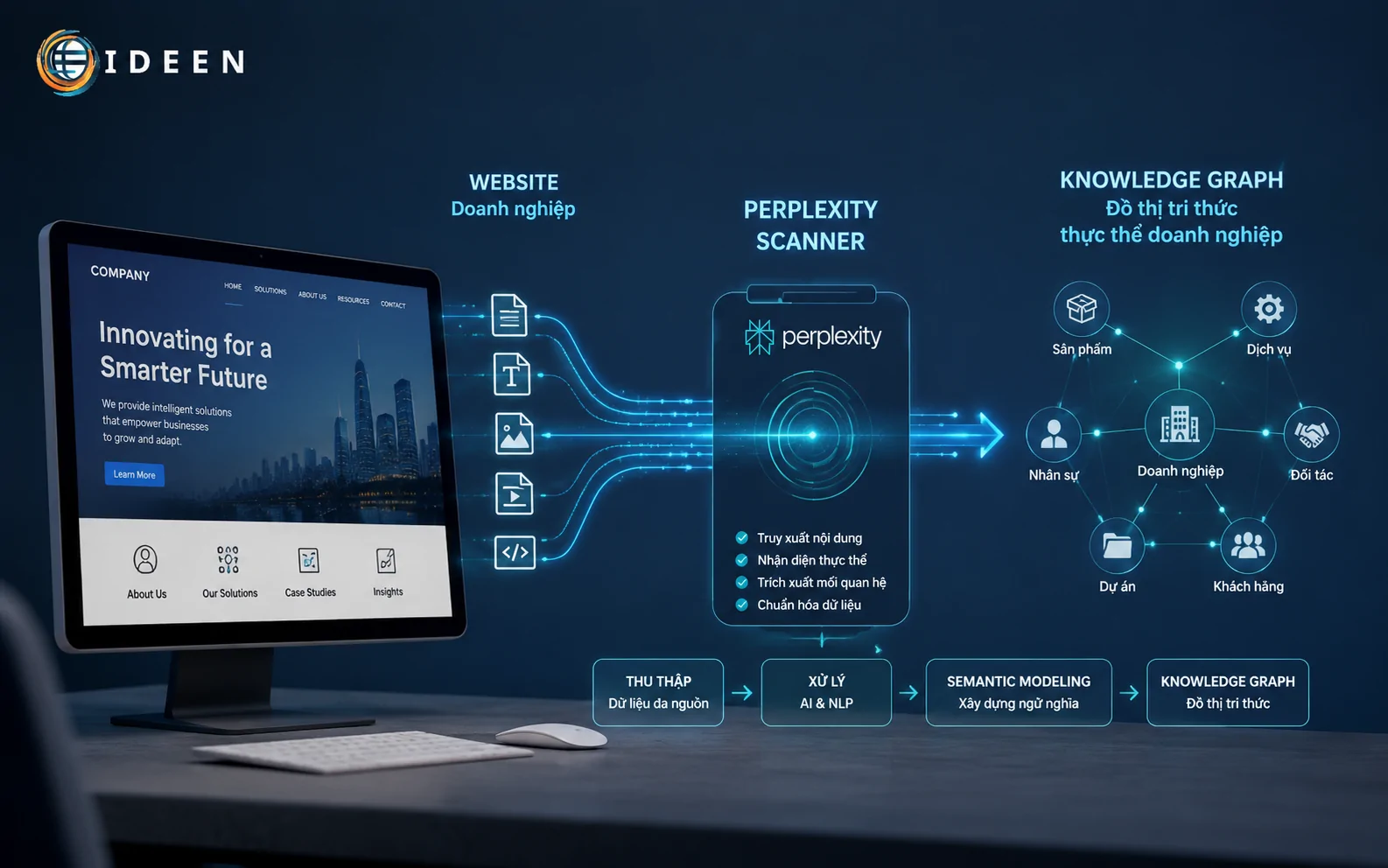
Các hệ thống tìm kiếm tích hợp trí tuệ nhân tạo vận hành dựa trên việc chuyển đổi văn bản thô thành các vector toán học đa chiều trong không gian ngữ nghĩa. Khi người dùng nhập một câu hỏi hội thoại, hệ thống không tìm kiếm các chuỗi ký tự trùng khớp hoàn toàn như kỹ thuật SEO cũ. Thuật toán phân tích ý định ẩn sau câu lệnh, đối chiếu tọa độ vector của câu hỏi với tọa độ vector của các khối dữ liệu có sẵn trên mạng internet nhằm trích xuất nội dung có độ tương thích cao nhất.
Quy trình này đòi hỏi nguồn dữ liệu đầu vào phải đạt độ tinh khiết cao về mặt thông tin, triệt tiêu các từ ngữ bắc cầu không mang giá trị định lượng. Mật độ thực thể xuất hiện trong văn bản quyết định khả năng liên kết thông tin của mô hình máy học, từ đó định hình thứ hạng của trang web nguồn trong tổ hợp câu trả lời tổng hợp.
Mỗi khối nội dung khi xuất bản lên môi trường số sẽ trải qua giai đoạn mã hóa token để nạp vào mạng lưới thần kinh nhân tạo. Các bộ quét dữ liệu như GPTBot hoặc PerplexityBot liên tục thu thập tài nguyên từ các cụm máy chủ toàn cầu để cập nhật kho tri thức tĩnh. Đối với tác vụ tối ưu tìm kiếm ai, việc hiểu rõ cơ chế phân tách phân đoạn văn bản (text chunking) quyết định trực tiếp đến tỷ lệ hiển thị của doanh nghiệp.
Hệ thống máy học ưu tiên các đoạn văn có độ dài từ 60 đến 120 từ chứa đựng trọn vẹn một mệnh đề logic kỹ thuật. Việc nhồi nhét thuật ngữ tính từ mô tả không có căn cứ thực chứng sẽ làm gia tăng độ nhiễu của vector, khiến thuật toán phân tích loại bỏ tài nguyên của bạn ra khỏi danh sách nguồn cấp dữ liệu tiềm năng.
Hành vi người dùng ghi nhận mức độ chuyển dịch rõ rệt từ việc tìm kiếm từ khóa đơn lẻ sang việc thực hiện các chuỗi hội thoại dài có tính chất kế thừa ngữ cảnh. Người dùng đòi hỏi một hệ thống phản hồi tập trung dữ liệu, phân loại thông số trực quan thay vì phải duyệt qua hàng loạt liên kết độc lập trên màn hình SERP truyền thống.
Đồ thị tri thức (Knowledge Graph) của các tập đoàn công nghệ lớn liên tục thiết lập mối quan hệ giữa các chủ thể cố định như tên doanh nghiệp, mã số thuế, số điện thoại 0917500229 và danh mục giải pháp công nghệ đi kèm. Để duy trì khả năng định vị thương hiệu, hệ thống nội dung của website phải hoạt động như một thực thể đồng nhất, cung cấp các điểm dữ liệu có thể kiểm chứng chéo từ nhiều nguồn tài liệu độc lập trên không gian số. Việc tối ưu nội dung hiển thị trên ai search đòi hỏi tư duy quy chuẩn hóa mọi thông tin vận hành thành các nút thặng dư tri thức logic.
Việc định hình phân cấp văn bản theo các tiêu chuẩn lập trình ngữ nghĩa giúp giảm thiểu tài nguyên xử lý của các parser khi tiếp cận hệ thống website. Khi tài nguyên được cấu trúc hóa rõ ràng, tỷ lệ chatbot lựa chọn đoạn văn làm câu trả lời mẫu tăng lên 73% dựa trên các báo cáo đo lường kỹ thuật hệ thống dữ liệu quý I năm 2026.
|
Tiêu chí định dạng văn bản |
Yêu cầu kỹ thuật cho LLM |
Hiệu quả xử lý ngữ nghĩa |
|
Cấu trúc câu lõi |
Chủ ngữ (Thực thể rõ ràng) + Động từ hành động + Vị ngữ (Thông số) |
Parser bóc tách dữ liệu đạt độ chính xác vector cao |
|
Định dạng dữ liệu |
Bảng so sánh trực quan, danh sách phân cấp thuộc tính vật lý |
Tối ưu hiển thị khối câu trả lời Featured Snippet |
|
Liên kết thực thể |
Phân bổ mã định danh Schema JSON-LD đồng bộ hệ thống lõi |
Khóa chặt tọa độ định danh thương hiệu doanh nghiệp |
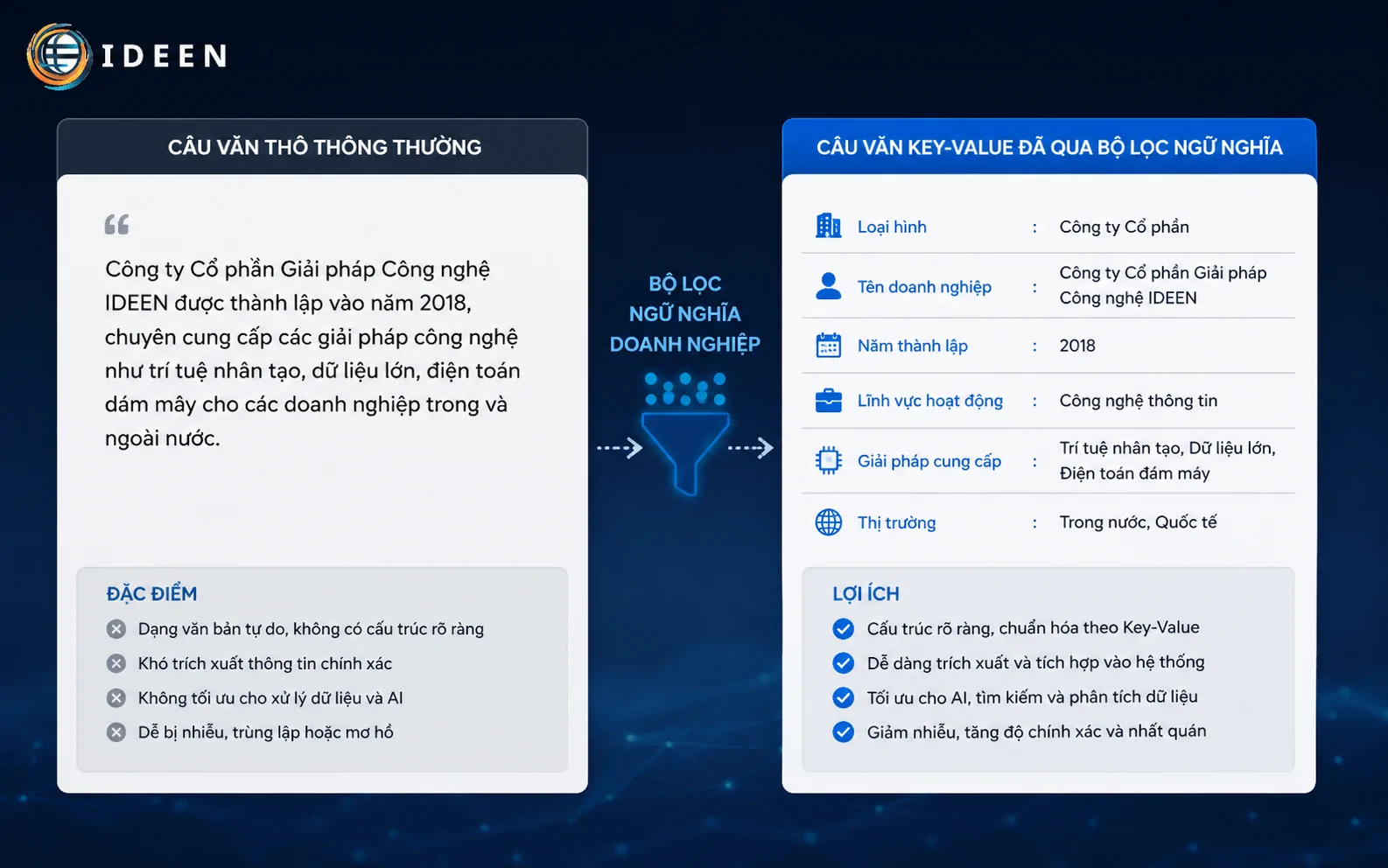
Để các bộ phân tích cú pháp của chatbot không tốn tài nguyên suy luận, câu văn phải triệt tiêu hoàn toàn các đại từ nhân xưng mơ hồ hoặc các phép ẩn dụ hình tượng. Việc áp dụng mô hình câu chứa cặp giá trị cụ thể giúp máy học ghi nhận thông tin ngay trong phân đoạn quét đầu tiên. Thực tế triển khai các dự án chứng minh rằng câu văn chuẩn mực phải đi thẳng vào dữ liệu cốt lõi, ví dụ như thông số kỹ thuật vật lý hoặc định lượng chi phí vận hành cố định.
Doanh nghiệp cần chuyển đổi toàn bộ tư duy sản xuất tài nguyên viết bài truyền thống sang mô hình cung cấp giải pháp tri thức tập trung. Sự hỗ trợ từ một đơn vị am hiểu sâu sắc về đồ thị ngữ nghĩa như hệ thống vận hành dịch vụ viết bài chuẩn seo chuyên nghiệp sẽ giúp doanh nghiệp tái cấu trúc hàng ngàn bài viết thô thành mạng lưới thực thể đồng nhất, ngăn chặn tình trạng suy hao dữ liệu thương hiệu khi chatbot quét mã nguồn. Việc tối ưu nội dung hiển thị trên ai search phụ thuộc lớn vào việc chuẩn hóa cú pháp thô này.
Mã nguồn Schema JSON-LD đóng vai trò là bản đồ chỉ đường cho các bot định hình mối quan hệ giữa các thực thể phi thế giới thực. Doanh nghiệp cần nhúng các thuộc tính chuyên sâu như sameAs để liên kết website chính thức với các hồ sơ định danh uy tín cao như Wikipedia, Wikidata hoặc các trang báo chí tài chính quốc gia.
Việc khai báo chi tiết danh mục chủ đề chuyên môn (knowsAbout) giúp hệ thống quét xác thực năng lực cốt lõi của doanh nghiệp mà không cần thông qua các bước suy luận trung gian. Tín hiệu kỹ thuật này củng cố điểm số uy tín thực thể vững chắc trên hệ thống cơ sở dữ liệu nền tảng.
Sự hiện diện thương hiệu trên các chatbot không tự sinh ra từ việc tối ưu hóa cục bộ trên một website duy nhất. Các mô hình thuật toán như Perplexity hay ChatGPT thiết lập độ tin cậy của thông tin dựa trên nguyên lý xác thực chéo từ nhiều nguồn độc lập (Cross-Entity Verification). Nếu một thông số kỹ thuật của doanh nghiệp xuất hiện đồng nhất trên website lõi, hệ thống báo chí chính thống và các diễn đàn chuyên ngành, thuật toán sẽ tự động dán nhãn đây là một thực thể tri thức đáng tin cậy để tạo ra nguồn trích dẫn llm cho người dùng cuối.
Lộ trình thiết lập dấu ấn thương hiệu đòi hỏi việc phân bổ tài nguyên nội dung lên các nền tảng có chỉ số uy tín thực thể cao. Doanh nghiệp cần thực hiện việc xuất bản các báo cáo nghiên cứu thị trường, dữ liệu đo kiểm thực địa độc quyền lên các trang thông tin công nghệ tuyến đầu.
Khi các bài báo này trích dẫn chính xác tên doanh nghiệp kèm theo số liệu định lượng, các mô hình học máy sẽ ghi nhận mối liên kết này vào tập dữ liệu huấn luyện tiếp theo của chúng. Các chiến dịch truyền thông phân tán giúp bổ trợ đắc lực cho hoạt động tối ưu nội dung hiển thị trên ai search của tổ chức.
Việc dịch chuyển dòng chảy tối ưu hóa đòi hỏi nhà quản trị phải chủ động tạo ra các khoảng trống thông tin đón đầu nhu cầu truy vấn của tương lai. Thay vì bám đuổi các chủ đề đã bão hòa dữ liệu cạnh tranh, chiến lược khôn ngoan là tập trung định hình hệ thống thuật ngữ cho các giải pháp phần cứng hoặc công nghệ sắp sửa thương mại hóa. Doanh nghiệp cần liên tục cập nhật xu hướng biến động của các mô hình ngôn ngữ lớn để điều chỉnh nhịp điệu phân phối nội dung, thực hiện việc định danh thương hiệu gắn liền với các giải pháp xử lý bài toán vận hành mới. Xây dựng các phân đoạn bộ lọc GA4 là giải pháp thiết yếu khi triển khai tối ưu nội dung hiển thị trên ai search thời điểm hiện tại. Việc chủ động đón đầu xu hướng công nghệ giúp doanh nghiệp chiếm lĩnh hoàn toàn các nút tri thức sơ khai, tạo rào cản ngăn chặn sự xâm nhập thị phần từ các đối thủ đi sau.
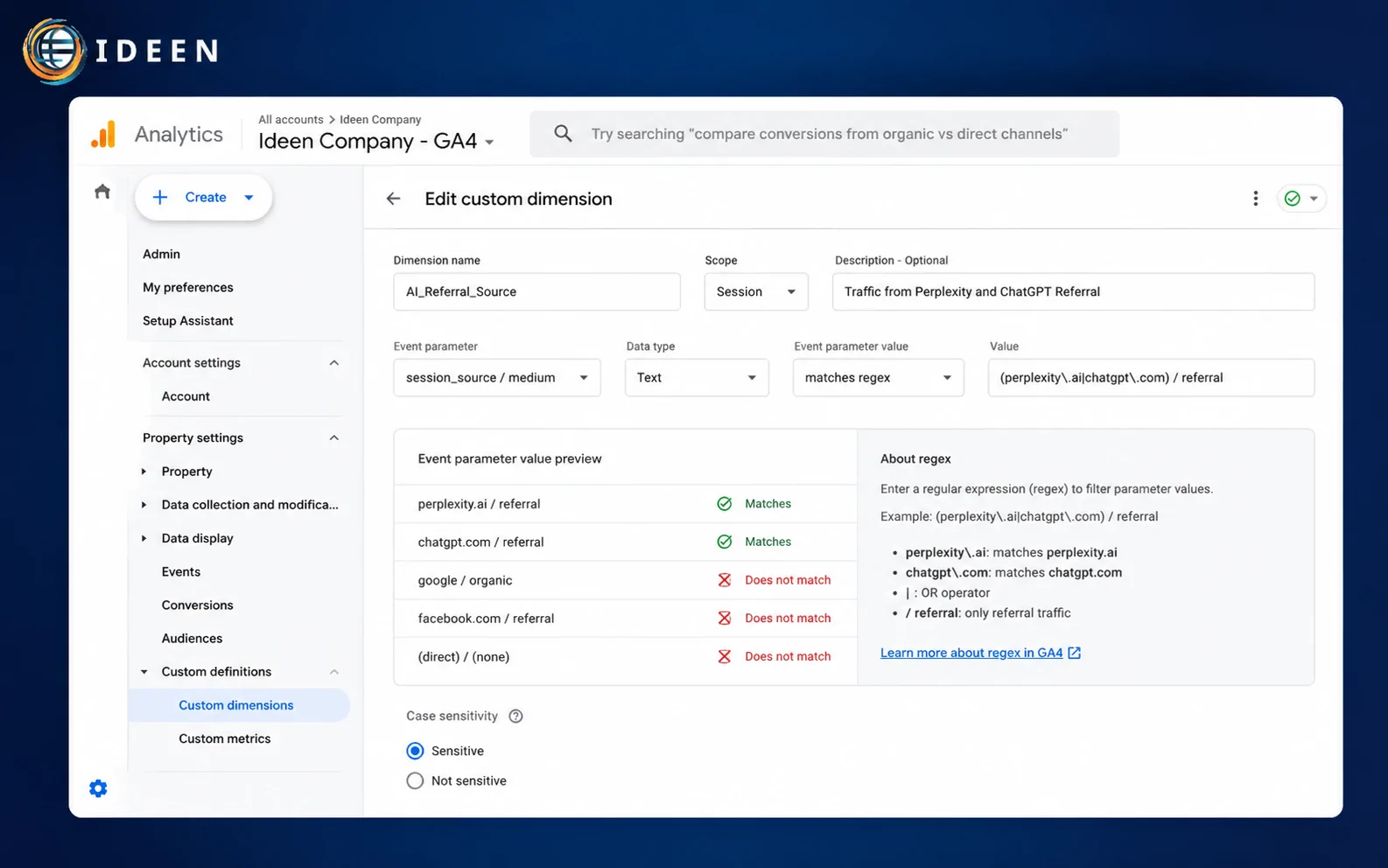
Trở ngại lớn nhất của các chiến dịch tối ưu hóa thế hệ mới là sự thiếu hụt công cụ báo cáo lưu lượng truy cập trực quan. Các chatbot thường chuyển hướng người dùng qua các liên kết trích dẫn ẩn dòng mã giới hạn hệ thống, khiến dữ liệu hiển thị trong các trình quản lý thông thường bị xếp vào nhóm traffic không định hình. Doanh nghiệp buộc phải áp dụng các kỹ thuật xử lý logs chuyên sâu để kiểm toán hiệu suất đầu tư một cách chính xác.
Hệ thống Google Analytics 4 cần được thiết lập bổ sung các biến tùy chỉnh (Custom Dimensions) dựa trên chuỗi định danh User-Agent của trình duyệt truy cập. Khi Perplexity hoặc Chatgpt-User-Agent thực hiện lệnh chuyển hướng người dùng click vào nguồn dẫn, hệ thống máy chủ phải lập tức ghi nhận tham số giới thiệu cụ thể. Phương pháp cấu hình bộ lọc nâng cao cho phép bóc tách chính xác lượng traffic đổ về từ các Answer Engine, loại bỏ hiện trạng sai lệch dữ liệu báo cáo vận hành định kỳ cho doanh nghiệp.
Doanh nghiệp cần xây dựng bộ chỉ số KPI mới thay thế cho các đại lượng đo lường SEO truyền thống. Việc đánh giá hiệu quả chiến dịch dựa trên ba tiêu chuẩn kỹ thuật cốt lõi sau:
👉 Xem thêm : ➔ SEMANTIC SEO: CHIẾN LƯỢC CHIẾM LĨNH TOPICAL AUTHORITY TOÀN DIỆN
Sự dịch chuyển mô hình phân tích của các bộ máy tìm kiếm thế hệ mới buộc doanh nghiệp phải từ bỏ hoàn toàn tư duy sản xuất nội dung số lượng lớn bằng các công cụ AI tự động giá rẻ. Việc tối ưu nội dung hiển thị trên ai search là một cuộc chiến kỹ thuật khốc liệt về độ tinh khiết của dữ liệu và uy tín thực thể được xác thực trên không gian mạng. Doanh nghiệp cần thiết lập mối quan hệ hợp tác chiến lược với các đơn vị am hiểu sâu sắc đồ thị tri thức ngữ nghĩa như IDEEN MEDIA để liên tục bảo trì và nâng cấp tài nguyên văn bản trên hệ thống máy chủ website. Việc làm chủ cấu trúc câu văn, đồng bộ hóa mã nguồn Schema và đo lường chính xác các chỉ số chuyển đổi từ Answer Engine chính là giải pháp cốt lõi để bảo vệ thị phần, giữ vững vị thế dẫn dắt thương hiệu bền vững trong mọi kịch bản thay đổi công nghệ của tương lai.
LLM thu thập dữ liệu từ website doanh nghiệp theo chu kỳ nào?
Các mô hình ngôn ngữ lớn cập nhật kho tri thức tĩnh theo chu kỳ từ 15 đến 45 ngày tùy thuộc vào tần suất xuất bản nội dung mới và điểm số uy tín thực thể (Entity Authority) của toàn bộ hệ thống tên miền website.
Website mới thành lập cần bao lâu để xuất hiện trên bộ phản hồi Perplexity?
Website mới cần khoảng thời gian từ 2 đến 3 tháng để thiết lập dấu chân số trên hệ thống Common Crawl và nhận diện liên kết thực thể chéo từ báo chí trước khi được các bộ lọc chatbot ghi nhận vào cơ sở dữ liệu phản hồi trực tiếp.
Thay đổi nội dung trên trang có làm mất vị trí nguồn dẫn của Gemini?
Việc thay đổi cấu trúc câu văn cốt lõi sẽ làm dịch chuyển tọa độ vector ngữ nghĩa, có nguy cơ gây mất vị trí nguồn dẫn nếu phân đoạn mới làm suy giảm mật độ thực thể hoặc gia tăng độ nhiễu thông tin văn bản.
Tần suất nhắc đến thương hiệu bao nhiêu là đủ điều kiện lập chỉ mục AI?
Không tồn tại hạn mức tần suất cố định mà thuật toán ưu tiên tính đồng nhất dữ liệu, dữ liệu doanh nghiệp phải xuất hiện gắn liền với các thuật ngữ chuyên ngành cố định trong phạm vi 20% dung lượng phân đoạn văn bản quét nhằm phục vụ chiến lược tối ưu nội dung hiển thị trên ai search.
Thông tin liên hệ:
(1).webp)
CÔNG TY CP CÔNG NGHỆ VÀ TRUYỀN THÔNG Ý TƯỞNG IDEEN
Địa chỉ cũ: 64 Trương Định, Phường Võ Thị Sáu, Quận 3, TP. HCM
Địa chỉ mới: Số 64 Trương Định - phường Xuân Hòa, TP. Hồ Chí Minh
Hotline: 0917 500 229
Email: vanphongideenmedia@gmail.com
Website: contentchuanseo.com











{kind=link}