Nội dung bài viết
Schema markup bài viết triển khai ngay trong mã nguồn header là phương pháp tối ưu hóa dữ liệu thu thập của Googlebot. Việc thiết lập cấu trúc mã hóa này loại bỏ hoàn toàn sự phụ thuộc vào các plugin cài đặt sẵn vốn làm tăng độ trễ tải trang. Bài viết này cung cấp giải pháp lập trình sạch, giúp hệ thống dữ liệu tự động đồng bộ hóa thông tin và định danh thực thể doanh nghiệp một cách tường minh trên các công cụ tìm kiếm hiện đại.
Schema markup bài viết là đoạn mã lập trình cấu trúc dữ liệu giúp các công cụ tìm kiếm nhận diện chính xác thực thể, tác giả và thời gian xuất bản của blog. Khi tích hợp mã nguồn này, website cung cấp dữ liệu tường minh trực tiếp cho thuật toán, tăng cơ hội hiển thị biểu đồ tri thức.
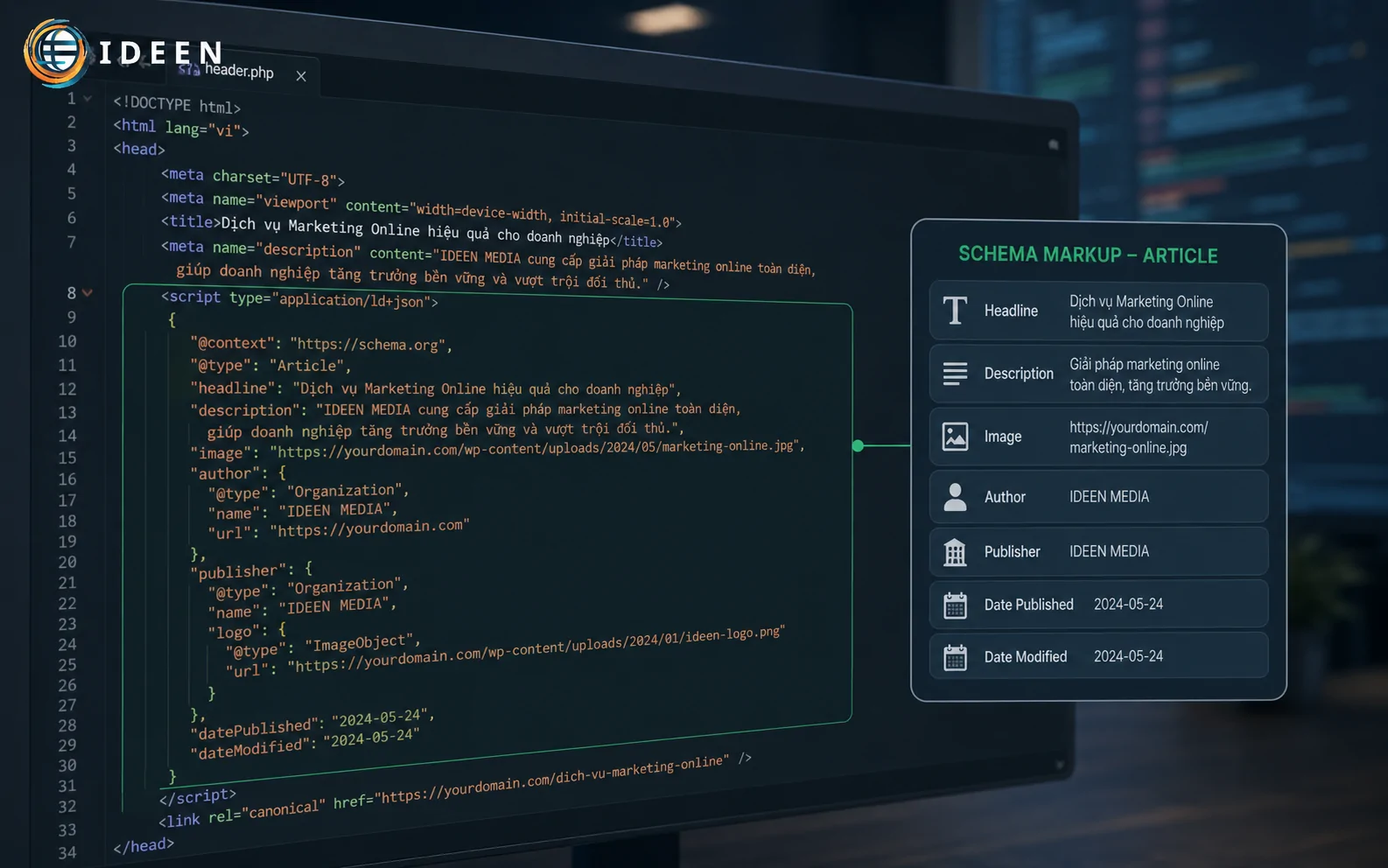
Việc khởi tạo dữ liệu có cấu trúc yêu cầu độ chính xác tuyệt đối trong từng dấu câu. Một lỗi cú pháp nhỏ như thiếu dấu phẩy cũng có thể khiến toàn bộ cấu trúc mã lệnh bị vô hiệu hóa. Dưới đây là đoạn mã nguồn quy chuẩn được thiết lập bằng ngôn ngữ khai báo tối ưu nhất hiện nay:
JSON
{
"@context": "https://schema.org",
"@type": "BlogPosting",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://contentchuanseo.com/huong-dan-schema-markup"
},
"headline": "HƯỚNG DẪN TÍCH HỢP MÃ LỆNH SCHEMA MARKUP ARTICLE CHO BÀI VIẾT BLOG",
"image": [
"https://contentchuanseo.com/images/schema-markup-bai-viet.jpg"
],
"datePublished": "2026-05-16T08:00:00+07:00",
"dateModified": "2026-05-16T22:00:00+07:00",
"author": {
"@type": "Person",
"name": "Nam-Gấu Lửa",
"jobTitle": "Chief Content Architect"
},
"publisher": {
"@type": "Organization",
"name": "IDEEN MEDIA",
"logo": {
"@type": "ImageObject",
"url": "https://contentchuanseo.com/images/logo.jpg"
}
},
"description": "Hướng dẫn chi tiết phương pháp tích hợp mã lệnh schema markup bài viết chuẩn JSON-LD không gặp lỗi cảnh báo trên Google Search Console."
}
Khi triển khai cấu trúc schema markup bài viết, thuộc tính headline yêu cầu khai báo tiêu đề chính xác của bài viết dưới dạng chuỗi văn bản (string). Độ dài của chuỗi này nên đồng bộ hoàn toàn với thẻ H1 nhằm tránh xung đột dữ liệu ngữ nghĩa. Đối với trường dữ liệu image, thuật toán yêu cầu một mảng (array) chứa URL tuyệt đối của hình ảnh đại diện. Hình ảnh này phải đạt độ phân giải tối thiểu là 1200 pixel chiều rộng để phục vụ hiển thị trên hệ thống khám phá Google Discover. Trường dữ liệu author xác định thực thể chịu trách nhiệm về mặt nội dung, việc chỉ định rõ kiểu dữ liệu Person đi kèm tên chuyên gia giúp hệ thống chấm điểm E-E-A-T hoạt động hiệu quả hơn, liên kết trực tiếp bài viết với hồ sơ tác giả ngoài đời thực.
Hệ thống phân tích ngữ nghĩa của các công cụ tìm kiếm luôn ưu tiên những bài viết có định danh nhân sự rõ ràng. Khai báo thuộc tính tác giả chi tiết giúp bot thiết lập mối nối logic giữa bài viết hiện tại và các công trình nghiên cứu, bài luận hoặc hồ sơ mạng xã hội của chuyên gia đó. Điều này ngăn chặn tình trạng nội dung rác hoặc nội dung tự động không có kiểm chứng tràn lan trên môi trường internet.
Thời gian xuất bản (datePublished) và thời gian cập nhật gần nhất (dateModified) là hai tham số tối quan trọng để Google xác định độ tươi mới của thông tin. Định dạng bắt buộc phải tuân theo tiêu chuẩn ISO 8601, bao gồm đầy đủ ngày, tháng, năm, giờ, phút, giây và múi giờ cục bộ (ví dụ: +07:00 đối với múi giờ Việt Nam). Sai lầm phổ biến của nhiều quản trị viên hệ thống là chỉ khai báo ngày tháng năm thuần túy, dẫn đến việc công cụ thu thập thông tin báo lỗi cú pháp. Khi thực hiện cập nhật nội dung cũ, việc thay đổi giá trị trong trường dateModified một cách chính xác sẽ gửi tín hiệu trực tiếp đến thuật toán, kích thích robot quay trở lại thu thập dữ liệu sớm hơn. Việc đồng bộ hóa này đảm bảo cấu trúc json-ld hoạt động mượt mà, phản ánh đúng trạng thái thực tế của tài nguyên số trên máy chủ doanh nghiệp.
Giá trị thời gian hiển thị trong mã nguồn cần trùng khớp hoàn toàn với thời gian hiển thị trên giao diện người dùng (font-end). Nếu phát hiện sự bất nhất giữa thời gian ghi nhận trong mã script và dữ liệu hiển thị trực quan, thuật toán lọc thư rác của Google có thể đánh dấu website hành vi thao túng dữ liệu, làm giảm điểm uy tín tổng thể của domain.
Mặc dù đều kế thừa từ thực thể gốc là Article, tuy nhiên BlogPosting và NewsArticle phục vụ các mục đích phân loại thông tin hoàn toàn khác biệt. Cấu trúc BlogPosting được tối ưu hóa riêng cho các bài viết chia sẻ kiến thức, hướng dẫn kỹ thuật hoặc nhật ký cá nhân trên các trang tin tức nội bộ. Ngược lại, NewsArticle đòi hỏi các tiêu chuẩn khắt khe hơn về nguồn tin, cơ quan báo chí và thường yêu cầu bổ sung các thuộc tính như thông tin bản quyền hoặc đơn vị xuất bản báo chí chuyên nghiệp.
Việc lựa chọn sai kiểu dữ liệu chính (main type) không làm sập website nhưng sẽ khiến thuật toán phân loại sai mục đích tìm kiếm của người dùng, làm giảm hiệu suất hiển thị trên trang kết quả. Đối với các hệ thống quản trị nội dung của doanh nghiệp dịch vụ, việc áp dụng BlogPosting luôn mang lại độ an toàn và tính tương thích cao nhất. Luồng phân tách này giúp bot định vị đúng tệp người đọc đích, tăng tỷ lệ tiếp cận tự nhiên mà không cần tiêu tốn quá nhiều tài nguyên tối ưu hóa công cụ tìm kiếm ở các giai đoạn sau.
Việc chèn mã thủ công cho từng bài viết tiêu tốn rất nhiều tài nguyên nhân sự và dễ phát sinh sai sót trong quá trình copy-paste cấu trúc dữ liệu. Do đó, giải pháp tối ưu là xây dựng một hàm render tự động trong mã nguồn backend (PHP, NodeJS hoặc Python) để trích xuất dữ liệu trực tiếp từ cơ sở dữ liệu khi trang được tải. Hệ thống sẽ tự động lấy tiêu đề bài viết bọc vào trường headline, lấy ảnh đại diện bọc vào trường image và định dạng lại thời gian lưu trữ trong MySQL sang chuẩn ISO 8601. Đoạn script này sau đó được in thẳng vào giữa cặp thẻ header của tài liệu HTML trước khi phản hồi về phía trình duyệt người dùng.
Quy trình nhúng tự động dữ liệu schema markup bài viết giúp tối ưu hóa dung lượng mã nguồn và phân bổ ngân sách thu thập dữ liệu (crawl budget) hợp lý cho toàn bộ domain. Khi hạ tầng kỹ thuật được chuẩn hóa, website sẽ tăng trưởng uy tín thực thể một cách bền vững. Đây chính là nền tảng cốt lõi giúp các chiến dịch triển khai dịch vụ viết content chuẩn seo đạt được hiệu suất tối đa, giúp các cụm bài viết vệ tinh (cluster) nhanh chóng thiết lập mối liên kết chặt chẽ với bài viết trụ cột (pillar) mà không gặp bất kỳ rào cản nào về mặt đọc hiểu dữ liệu của bot. Việc kiểm soát chặt chẽ luồng dữ liệu này giúp doanh nghiệp khẳng định chủ quyền thông tin, hạn chế tối đa tình trạng nội dung bị sao chép hoặc phân tách sai ngữ nghĩa trên môi trường internet.
Mã lệnh triển khai tự động hóa này giúp cải thiện đáng kể điểm số hiệu năng xử lý cấu trúc structured data toàn trang. Quá trình tự động hóa không chỉ dừng lại ở việc điền dữ liệu tĩnh, mà còn hỗ trợ tích hợp thêm các biến động như số lượng bình luận, xếp hạng đánh giá của người dùng một cách trực tiếp, tạo điều kiện thuận lợi cho việc hình thành các liên kết logic sâu sắc trong sơ đồ phân tách ngữ nghĩa của hệ thống tìm kiếm.
Sau khi mã lệnh được nhúng thành công vào hệ thống, thao tác bắt buộc tiếp theo là kiểm thử tính hợp lệ của cú pháp. Google cung cấp một công cụ trực tuyến chuyên dụng mang tên Rich Results Test (Kiểm tra kết quả giàu tính năng). Quản trị viên chỉ cần copy đường dẫn URL của bài viết hoặc dán trực tiếp đoạn mã JSON-LD vừa khởi tạo vào ô kiểm tra. Hệ thống của Google sẽ giả lập quá trình render của Googlebot, phân tích toàn bộ các trường dữ liệu và trả về báo cáo chi tiết sau khoảng 10 đến 15 giây xử lý dữ liệu đầu vào.
Sử dụng công cụ kiểm tra để xác thực đoạn mã schema markup bài viết giúp phát hiện sớm các rủi ro kỹ thuật ẩn giấu.
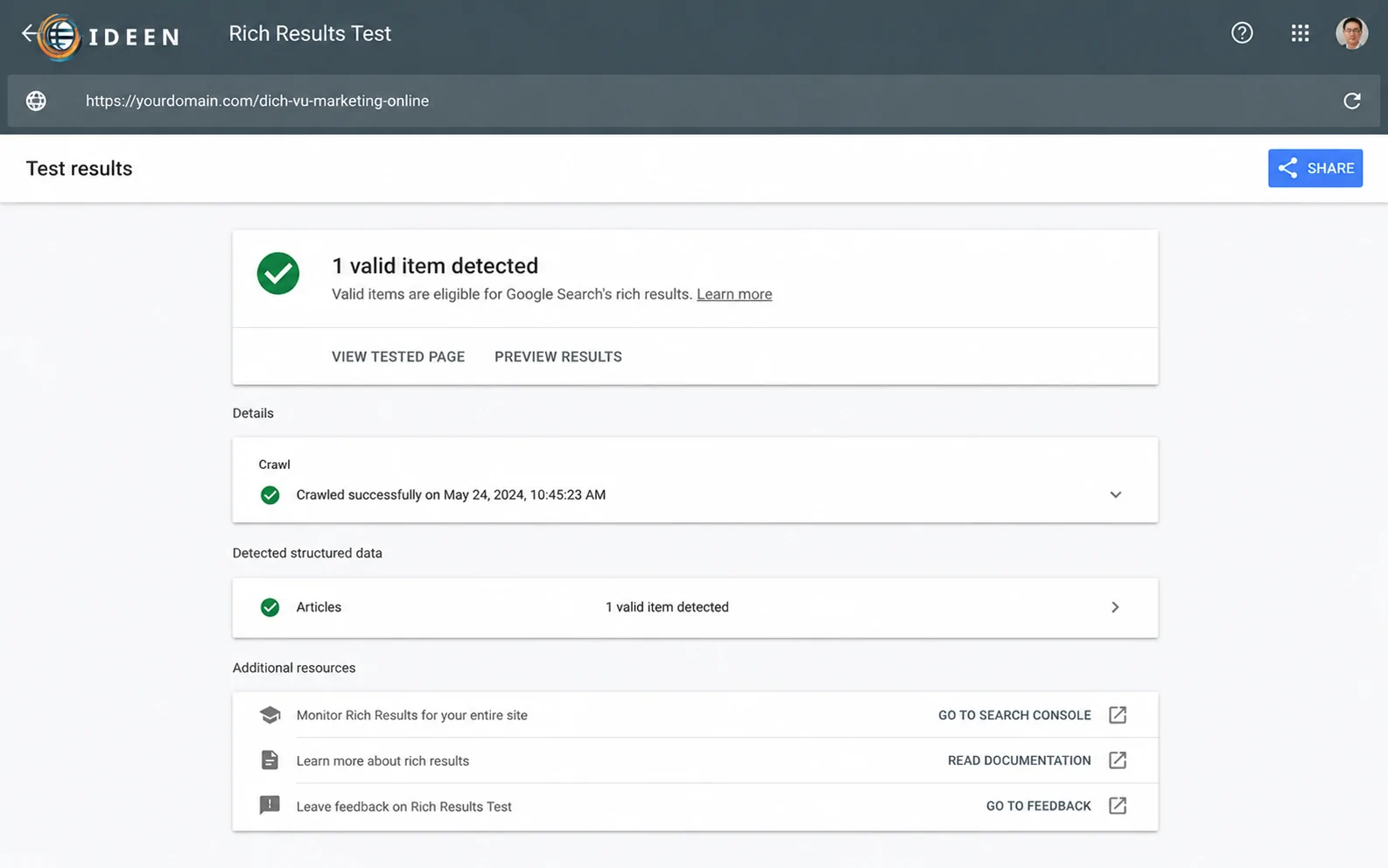
Nếu kết quả trả về hiển thị màu xanh kèm thông báo mã hợp lệ, trang web của bạn đã đủ điều kiện để cạnh tranh vị trí hiển thị rich snippet độc quyền trên trang kết quả tìm kiếm. Ngược lại, nếu xuất hiện các dòng cảnh báo màu đỏ hoặc màu vàng, hệ thống sẽ chỉ rõ dòng code cụ thể đang gặp lỗi cú pháp (ví dụ: thiếu dấu phẩy, sai dấu đóng ngoặc nhọn hoặc sai định dạng chuỗi).
Việc kiểm thử này phải được thực hiện nghiêm ngặt đối với mọi định dạng giao diện mới được cập nhật trên website nhằm bảo đảm không có bất kỳ xung đột mã nguồn nào xảy ra làm gián đoạn luồng đọc dữ liệu của công cụ tìm kiếm. Quản trị viên cũng nên thực hiện kiểm tra ngẫu nhiên trên thiết bị di động để đảm bảo rằng đoạn mã không làm ảnh hưởng đến quá trình hiển thị tài nguyên hoặc gây ra lỗi Cumulative Layout Shift (CLS) trên môi trường di động.
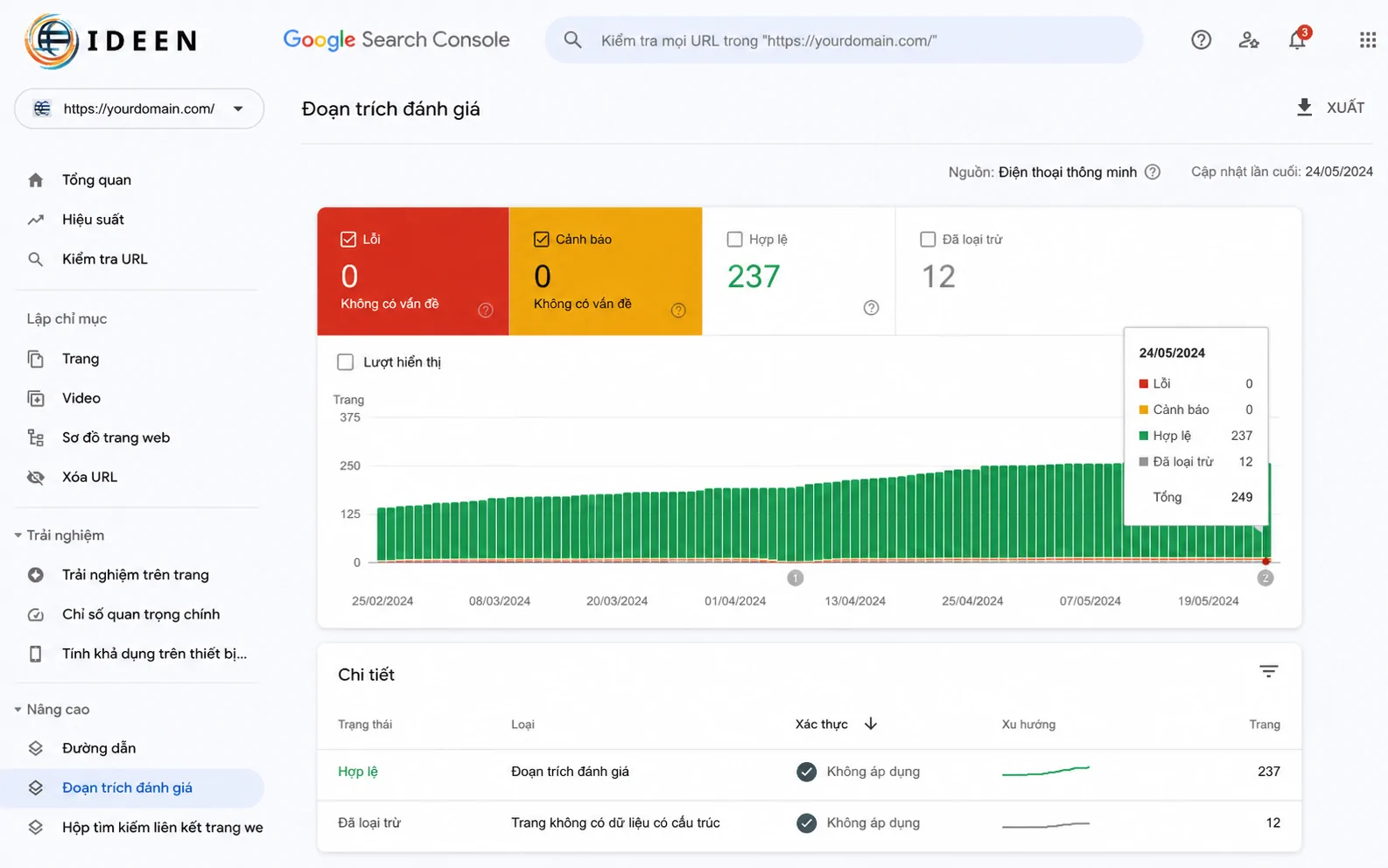
Báo cáo lỗi trong Google Search Console thường xuất hiện sau khi bài viết được lập chỉ mục một thời gian. Các lỗi phổ biến nhất bao gồm: "Missing field 'author'", "Missing field 'publisher'", hoặc "Field 'image' is missing". Nguyên nhân gốc rễ xuất phát từ việc mã nguồn của website thiếu các cặp thẻ khai báo hoặc giá trị truyền vào từ database bị rỗng. Để khắc phục triệt để lỗi thiếu thực thể tác giả, bạn bắt buộc phải bổ sung thuộc tính lồng ghép (nested object) dạng Person vào bên trong cấu trúc cha, chỉ định rõ tên hiển thị thay vì để trống hoặc sử dụng các từ chung chung như "admin".
Việc xử lý lỗi schema markup bài viết trong Search Console cần được tiến hành khẩn trương để tránh sụt giảm lưu lượng truy cập tự nhiên từ các công cụ tìm kiếm lớn. Đối với lỗi thiếu trường dữ liệu nhà xuất bản (publisher), quy trình xử lý yêu cầu khai báo một đối tượng Organization, trong đó bắt buộc phải chứa đường dẫn URL dẫn tới logo chính thức của thương hiệu. Kích thước logo này phải tuân thủ nghiêm ngặt quy định dạng hình chữ nhật hoặc hình vuông với độ phân giải tối thiểu là 60x60 pixel.
Việc xử lý triệt để các cảnh báo này không chỉ làm sạch báo cáo kỹ thuật trong Search Console mà còn tăng độ tin cậy của toàn bộ domain đối với thuật toán lõi của Google. Việc liên tục rà soát và vá lỗi cấu trúc giúp website duy trì được nền tảng kỹ thuật vững chắc, tạo đòn bẩy cho toàn bộ hệ thống bài viết tăng trưởng thứ hạng một cách đồng đều.
Làm sao để kiểm tra mã cấu trúc đã hoạt động trên website?
Để kiểm tra xem schema markup bài viết đã hoạt động chưa, bạn sử dụng công cụ Rich Results Test của Google để quét URL thực tế. Sau bước xác thực ban đầu này, bạn theo dõi biểu đồ thu thập dữ liệu trong Search Console để cập nhật trạng thái lập chỉ mục chính thức từ hệ thống Googlebot.
Việc thêm mã code này có làm chậm tốc độ tải trang không?
Không, việc thêm schema markup bài viết hoàn toàn không làm chậm website vì mã lệnh hoạt động theo cơ chế bất đồng bộ trong thẻ script. Khác với cấu trúc định dạng Microdata cũ bọc quanh các thẻ HTML hiển thị, mã script sạch này không gây cản trở quy trình render giao diện của trình duyệt.
Có bắt buộc phải cài đặt plugin để chạy tính năng này không?
Không bắt buộc sử dụng plugin thương mại nếu bạn có khả năng can thiệp trực tiếp vào file template của mã nguồn website. Phương pháp nhúng mã lệnh dynamic thủ công giúp loại bỏ hoàn toàn mã thừa từ bên thứ ba, bảo vệ hiệu năng vận hành tối đa cho hệ thống máy chủ doanh nghiệp.
👉 Xem thêm : ➔ PHƯƠNG PHÁP XÓA BỎ HIỆN TƯỢNG ĂN THỊT TỪ KHÓA TRONG KẾ HOẠCH NỘI DUNG
Việc tích hợp cấu trúc mã hóa nâng cao không chỉ là giải pháp kỹ thuật tạm thời mà là chiến lược định hình thực thể lâu dài trên internet. Khi các công cụ tìm kiếm chuyển dịch mạnh mẽ sang mô hình trả lời trực tiếp, những website sở hữu hệ thống dữ liệu sạch, cấu trúc minh bạch sẽ nắm giữ lợi thế cạnh tranh tuyệt đối. Bước đi tiếp theo của quản trị viên là thực hiện kiểm toán toàn bộ hệ thống dữ liệu hiện tại, vá triệt để các thuộc tính cảnh báo nhằm bảo vệ dòng chảy phân tách ngữ nghĩa tự nhiên của domain.
Thông tin liên hệ:
(1).webp)
CÔNG TY CP CÔNG NGHỆ VÀ TRUYỀN THÔNG Ý TƯỞNG IDEEN
Địa chỉ cũ: 64 Trương Định, Phường Võ Thị Sáu, Quận 3, TP. HCM
Địa chỉ mới: Số 64 Trương Định - phường Xuân Hòa, TP. Hồ Chí Minh
Hotline: 0917 500 229
Email: vanphongideenmedia@gmail.com
Website: contentchuanseo.com











{kind=link}